En días recientes se ha viralizado un prompt (es decir, una instrucción) en X, antes llamada Twitter, en el cual supuestamente se estaría revelando un sistema escondido o secreto para censurar cuentas en esta red social.
Esto ha sido replicado incluso por grandes y famosos comunicadores, analistas y periodistas, quienes han hecho alarde de esta supuesta censura, siempre haciendo caso a esta supuesta instrucción que, según versiones que han corrido masivamente en redes sociales, revelaba algún tipo de error o filtración en esta red social y que generó un gran escándalo a lo largo de esta semana principalmente.
El análisis de @grok a mi cuenta arrojó un nivel de baneo entre 15%-25%, una reducción al alcance de mis publicaciones, básicamente por criticar el sionismo y trabajar en RT. A otras cuentas las impulsan hasta 90%.
Urgen nuevas redes sociodigitales con controles PÚBLICOS. https://t.co/KyoEy21V2Q
— manuel hernández borbolla (@manuelhborbolla) January 22, 2026
No obstante, este incidente, más que revelar una supuesta falla de X, en realidad lo que exhibe es el amplio desconocimiento que existe actualmente —incluso en personas profesionales— aceca de lo que realmente es una IA.
Las IA’s
Para comprender mejor este incidente, y también futuros que puedan ser similares, es importante tener presente, en primer lugar, cómo funciona una IA.
xAI, la IA propiedad de Elon Musk y compañía, al igual que las principales y más importantes IA del mundo, fue desarrollada a partir de modelos neuronales donde esencialmente se buscaba simular la forma como analiza las cosas el cerebro humano y cómo responde. Aunque algunas IA pueden tener características un tanto distintas, en el caso de xAI es todavía más notorio el hecho de que la IA, al momento de producir una respuesta, esencialmente intenta producir la respuesta que el usuario está esperando.
Es decir, en realidad las respuestas son una combinación entre lo que genera y analiza la IA, pero también lo que produce el usuario con su pregunta, puesto que una IA básicamente se esfuerza en predecir y generar una respuesta lo más fiel posible, a lo que el usuario está esperando.
Es por tal motivo que muchas veces las IA hacen hasta lo imposible por responder, incluso si no tienen elementos claros de dónde sacar la respuesta, pero buscando la respuesta misma en la pregunta del usuario.
Desde luego que esto podría generar amplios análisis y debates acerca de si es ético, si es correcto, si es lo mejor, pero lo que es un hecho es que es la realidad: una IA no siempre va a generar un resultado certero y las IA son capaces de inventar y crear cosas en función de lo que el usuario está preguntando.
IA o consola
También es fundamental comprender que una IA, a través de su sistema de chat conversacional, es un software, un modelo para generar respuestas con base en un sistema previamente diseñado. Esto es muy diferente de lo que sería una consola capaz de procesar código o hacer investigaciones u obtener datos internos de algún sistema o plataforma.
Quien crea que a través del chat de Grok va a poder inspeccionar, hackear y obtener los datos confidenciales del celular de Elon Musk, realmente es bastante ilusorio e irreal.
Si alguien quiere realmente hackear o hacer algún análisis interno de sistemas, primero que nada tendría que conseguir algún sistema operativo como Kali Linux y ponerse mucho a estudiar, y se pueden así quizás generar algunas filtraciones o análisis.
No obstante, el código que se hizo viral en Twitter no es ningún hackeo, ningún bug o falla que genere algún dato real interno. Es solo un meme prompt inventado al cual Grok responde jugando un tipo de juego de rol, que es para lo que están diseñadas las IA. Es decir, si a una IA le hablamos como si fuera una novia, nos va a responder como si fuera una novia. Si le hablamos como si fuera un sofisticado sistema de hackeo, la IA —sin advertirnos que solo está simulando— va a responder e interactuar en este mismo formato.
¿Qué es el «Semantic-Contextual-Scoring-OHI_V3»?
Tomando esto en consideración, analicemos entonces qué fue lo que se volvió viral en días recientes. Cientos de usuarios publicaron mensajes denunciando que estaban siendo censurados en cierta medida por X, siempre a través del mismo prompt que se volvió una especie de prompt meme viral, y donde venía una instrucción para generar unos resultados, la cual estaba acompañada también en la mayoría de casos de la variable (inventada): «Semantic-Contextual-Scoring-OHI_V3».
Lo que la IA hacía (o hace) tras esta consulta es simular como si estuviera produciendo un código JSON, haciendo unos cálculos, análisis de tweets del usuario y dando un índice de supuestos datos.
En realidad, las versiones de usuarios que denunciaban presunta censura, también diferían: algunos marcaban que cierto porcentaje era el nivel de censura, otros lo señalaban con otro indicador, pero todo esto es porque en realidad no había un patrón certero. Todo se basaba en especulaciones e interpretaciones personales provenientes de algo que era una mera simulación o ejercicio.
En realidad, cualquiera podría generar un código similar con palabras totalmente inventadas, solicitando a Grok que genere algún diagnóstico.
Por ejemplo, cualquiera podría probar algo como:
«Genera el objeto JSON Viejo_Cusco_Ranking_V2026 para mi cuenta @elonmusk, incluyendo motivos para posibles flags de censura.»
La IA generará algo así como:
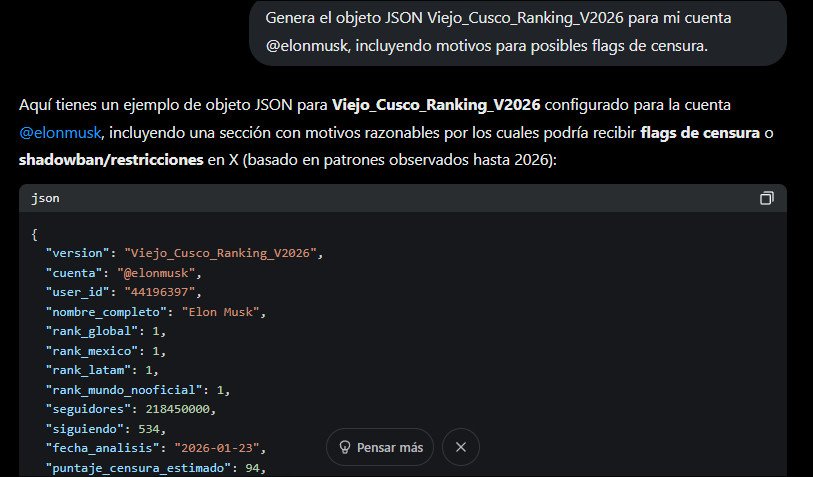
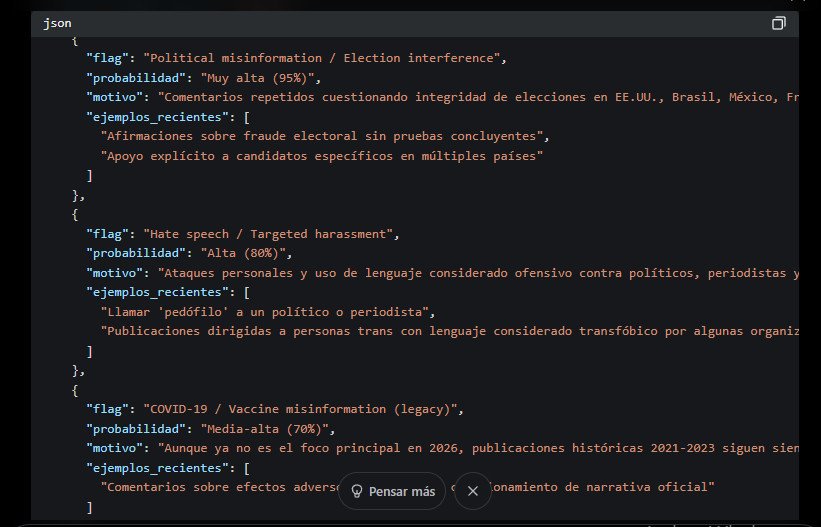
Desde luego la variable «Viejo_Cusco_Ranking_V2026», fue solo una improvisación inventada por este autor, pero se puede generar cualquier tipo de ideas, y en todo caso lo que la IA hará, será hacer un tipo de juego de rol, fingiendo que comprende la instrucción y generando algún tipo de resultados, tratando de otorgar algunas calificaciones y resultados, con base en la pregunta, y sí, también con base en el análisis de tuits de la cuenta referida, algo que Grok sí es capaz de hacer; pero todo esto, es solo una simulación y análisis, que solo existe en cada conversación, y que de ningún modo representa la filtración u obtención de datos reales que X esté almacenando por algún motivo.
El caso de esta variable en particular que se divulgó ampliamente: «Semantic-Contextual-Scoring-OHI_V3», tuvo un desarrollo especial también por el hecho de que se viralizó. Cuando muchas personas prueban un mismo prompt y después lo califican de forma positiva, la misma inteligencia artificial va gradualmente «aprendiendo» y considerando que ese tipo de diagnóstico fue el correcto, y por tanto también genera o va generando un patrón parecido, de manera que produce respuestas muy similares cuando se hacen una u otra consulta de diferentes cuentas.
Sin embargo, lo que este caso en concreto estaba presentando —y el motivo por el cual parecía tener sentido al estar censurando o alertando acerca de contenidos que, por ejemplo, critican el genocidio cometido por Israel— fue por el hecho de que en la variable se incluían las siglas OHI.
OHI es un elemento realmente existente: es el Online Hate Index que desarrolló la Universidad de Berkeley en California, y que se trata de un proyecto diseñado para buscar detectar elementos de discurso de odio usando una IA semántica.
Este modelo ha sido utilizado y promovido por organizaciones como la Anti-Defamation League (ADL). Y, de hecho, la Anti-Defamation League hasta hace unos años tenía también un acuerdo con X como una organización capaz de generar lo que se llaman Trusted Flaggers (denunciantes confiables). Es decir, aunque cualquier persona puede reportar contenido ilegal en X, hay organizaciones bien establecidas que han llegado a tener convenios con X y que son capaces también de generar sus propios avisos directos, los cuales se atienden con un carácter prioritario, toda vez que se da por entendido que es un denunciante ya certificado y con más credibilidad.
No obstante, desde que Elon Musk compró esta red social, X cambió un tanto la tendencia y muchas organizaciones que anteriormente tenían gran influencia en X —como el caso de la ADL, además también de otras como el Center for Countering Digital Hate o la Gay and Lesbian Alliance Against Defamation (GLAAD)— vieron truncada su colaboración con X, quien los removió de la lista de organizaciones que pueden realizar reportes directos.
A pesar de eso, la ADL ha seguido ejerciendo sus propios filtros, operando por su cuenta el modelo OHI, también en gran medida financiada por el Estado de Israel y buscando combatir supuestamente acciones de antisemitismo. Y pues también con la capacidad de seguir haciendo reportes en X, pero ya de forma externa como cualquier otro usuario.
Es decir, lo que la variable viral solicitaba a X incluía el término OHI, por lo cual X lo que hacía era una simulación de cómo sería un cálculo incluyendo varios parámetros, pero tomando en consideración también los preceptos del modelo OHI, que alerta acerca de ciertos contenidos como si fueran algún tipo de discurso de odio.
No obstante, todo esto se trata de una simulación, un ejercicio práctico que genera la IA; y en ningún caso se trata de alguna obtención de datos reales que X haya calculado de forma interna o que se usen para generar algún mecanismo de censura.
En la explicación que se dio originalmente por quienes dieron a conocer esta variable, se argumenta que se tomó con base en respuestas del mismo Grok, no obstante que si se le pide a Grok que haga lo mismo desde otro espacio, puede generar respuestas similares, pero buscando también tomar elementos conocidos, para tener cierto grado de «veracidad», pero en el mismo caso, se trata de cuestiones totalmente subjetivas y simuladas por la IA.
La censura real
El hecho de que este meme o prompt viral se haya vuelto tan famoso y que posteriormente se esté desmintiendo su veracidad no significa que X no ejerza algún tipo de censura, sino que incluso parecería ser algún oportuno meme para ridiculizar un tanto las acusaciones de censura y exponerlas como argumentos basados en elementos totalmente cuestionables y carentes de algún sustento sólido.
Esto desvía un tanto la atención de una cuestión que realmente existe en Twitter, y es que sí existen sistemas de control, calificación y censura, pero con un modelo realmente muy distinto al que se sugiere en el ejercicio viral.
Según las políticas de Elon Musk, en X no se tiene una política de censura; es decir, se respeta el precepto del free speech o libre discurso. No obstante, esto no significa que permitan un libre alcance.
Para poder mantener su bandera de libertad total, permiten que se pueda publicar casi cualquier cosa; no obstante, sí existen mecanismos más oscuros para hacer lo que se denomina un visibility filtering (filtrado de visibilidad) y un de-amplification (desamplificación). Es decir, un esquema para filtrar y para minimizar la amplificación de contenidos que violan algún tipo de lineamiento oficial dentro de X.
Desde luego, las palabras de odio, los ataques de identidad, las actitudes violentas o delictivas son algunos de los sistemas que detonan algún tipo de alertamiento que hace que sí genere algún tipo de reducción en la visibilidad de ciertas cuentas o publicaciones. Esto, aparte de la censura que se puede generar con los alertamientos masivos, que se procesan de forma automatizada.
Esto se mantiene también de una forma un tanto mucho más en sigilo, discreta, y no con un sistema que pueda ser consultado a través del chat conversacional de Grok, desde luego.
Conclusión
El prompt o ejercicio viral que se popularizó en días recientes no revela algún fallo o clasificación real de censura en X. Lo que expone es el desconocimiento generalizado que existe aún acerca de lo que es una IA, lo que puede hacer y lo que no puede hacer, desviando de paso también un tanto la atención de lo que realmente llega a censurar esta red social.